How to scale the root?
One topic in Yeti DNS research agenda is about the DNS root scaling issues. However, when different people talking about the root scaling issue they may have different context in their mind. One is about the root zone augmentation and impact[1][2], which is closely related to ICANN’s New gTLD program. Another one is about how to pervasively replicated and distribute the root zone file[4][5]. Yeti is considered the later scenario, but combined with the consideration for the issues of external dependency and surveillance risk.
Different from related discussion and proposal, Yeti adopt a straightforward approach by setting up 25 IPv6-only root name servers beyond the limitation of magic number of “13”. So far, no notable system outage and failures reported by our monitoring system and end users who made conscious decision to join the experimental, non-production system.
This article revisits “magic 13” briefly for audiences without the background, explores what a appropriate number is, and introduces what is the case in Yeti.
The Brief Background of Magic Number “13”
People have questions on the limitation of the number of DNS name server. One typical case is 13 root letters,the name server of the root (“.”). I remember 5 years ago, I was the guy who public asked the very questions: “why there are only 13 root letters”. Today in ICANN RSSAC public meeting and related mailing list, the question still bounces from time to time. From my 5 years experience on DNS Root issues, I can see there are at least 2 aspects in which people are prudent on scaling the DNS name server system, especially the Root. (More reading on that topicThe Root of the DNS and RSSAC028)
1) Historical choice and operational inertia
RFC1035 is frequently referred as the “initiator” for the limited space for DNS message over UDP. Because at that time, 30 years ago, the poor network condition did not support large datagrams or fragments, partially due to limited host’s buffer. IPv4 MTU is set 576 octets which requires a proper size limit on DNS message. RFC1035 gives a way out that if the length of DNS message is greater than 512 octets, it should be truncated asking for DNS query over TCP.
From the operational point of view, UDP is preferred to TCP as the transmission protocol for DNS due to performance consideration. So not surpassing the size limit(512 octets) become a practical choice at that time. In addition, it is a operational inertia that the response to the NS query (like priming query) is always expected to carry complete information of NS server, both the NS records and the addresses. It in another way puts a constrain on the number of NS records.
After IPv6 and DNSSEC introduced, the normal response containing all IPv4/IPv6 addresses and DNSSEC signature already surpassed 512 octets. The size limit of 512 octets has long gone. However, the “Magic 13” as an operational choice and inertia has been observed not be loosened even after EDNS0 introduced and widely deployed during all these years.
Note that when Internet governance became popular these years, “more root” become a political sensitive topic and the inertia become harder.
2) IPv6 Fragmentation issue in DNS
IPv6 has a fragmentation model that is different from IPv4 – in particular, fragmentation always takes place on the sending host, and not on an intermediate router. Fragmentation may cause serious issues; if a single fragment is lost, it results in the loss of the entire datagram of which the fragment was a part, and in the DNS frequently triggers a timeout. It is known at this moment that only a limited number of security middle-box implementations support IPv6 fragments.
Some public measurements and reports [draft-taylor-v6ops-fragdrop],[RFC7872] shows that there is notable packets drop rate due to the mistreatment of middle-box on IPv6 fragment. One APNIC study [IPv6-frag-DNS] reported that 37% of endpoints using IPv6-capable DNS resolver cannot receive a fragmented IPv6 response over UDP.
Some root servers (A, B, G and J) truncate the response once the large IPv6 packet surpasses 1280 octets to avoid IPv6 fragmentation issue during ICANN KSK rollover process. Another APNIC study show that to avoid fragmentation surpassing the maximum Ethernet packets size of 1500 octets, 1500 octets will be a new size limit for DNS packets, given EDNS0 is widely deployed.
Limit of 13 NS records still applies?
After above analysis, instead of 512 octets, 1500 octets seems a practical and safe size limit to avoid fragmentation of outbound packets for both IPv4 and IPv6. Another calculation is necessary to find how many NS records (N) can be accommodated in this size limit.
--Header: 12 octets
--Question: 5 octets
--Answer: 31+15*(N-1) octets [calculated base on current naming scheme : x.root-server.net, which can be compressed]
--Additional: 16*N +28*N [each A record is 16 bytes, and each AAAA record is 28 bytes]
If 512 octets still applies, than we should got N in the formula below:
12+5+31+15*(N-1)+16*N +28*N <512, then Maximum N = 8
If we put 1452 octets (1500-40-8) as the size limit, we got N=24. If the roots are IPv6 only, we got:
12+5+31+15*(N-1)+28*N <1452, then Maximum N =33
If consider the DNSSEC signature (RSA/SHA-256)in the response, when DO bit is set in NS query, then extra 286 octets(RRSIG) and 11 octets(OPT RR) is required in the DNS packet. Then we got N = 19 for dual-stack, N=26 for IPv6-only.
Worthwhile to mention that all calculation above is based on the assumption that the response to NS query contains all NS records and address information. According to the section 4.2 of RFC8109, if the additional section of DNS response may omit certain root server address information, the recursive resolver can to issue direct queries for A and AAAA RRsets for the remaining names. So if the address information is no required or partially required in the response, there are more space for NS records to be carried. There are cases in Yeti DNS testbed where the server only return NS records, or return small part of address information.
So as to the question “Does the limit of 13 NS records still applies?”. We can confidently say that the technical limit of 13 NS records has long gone but the operation inertia in people’s mind exists.
A performance test for many NS servers
Since the DNS size limit takes UDP as the default transmission protocol. People may think using TCP or DOH(DNS over HTTPs) to break the limit. To understand the performance difference of UDP and TCP with many NS servers, we conduct a simple lab test for that purpose.
The configuration is simple that a client directly connected with a server (Dell R320, 8G DDR, CentOS6.4, BIND9.9.5). The client using querytcp and queryperf to launch queries via TCP and UDP respectively. tcp_client is set 10000 in named.conf. The name in NS record is constructed in a format “x.root-servers.net” in which x is natural number starting from 1. When more names add to the NS RR, we record the qps as the performance metrics. Since EDNS0 support 4096 octets, more names (more than 270 names) will cause truncation and fallback to TCP. So we only test from 13 names to 200 names to explore the trend. The diagram below shows that the packets size increase and the qps of UDP DNS is rapidly decrease.
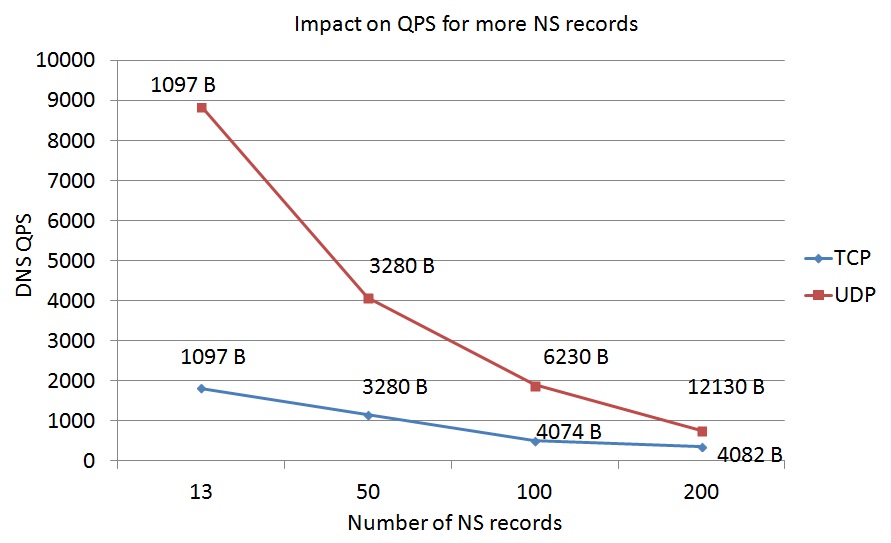
Regardless of fragmentation issue, Using either UDP or TCP with many NS records will introduce impact on the QPS of authoritative server. In addition there is a concern that too many records may require extra resource on recursive server to keep track the state of each server, doing RTT-sorting and recording EDNS0 support etc.
For modern resolver CPU and RAM related resource is not the bottle neck, compared to timeout and latency due to network failures and switching from one name server to another. So the practical and safer choice is continue to keep a fixed number of NS record (but not 13) and return as much address information as possible if UDP is chosen.
I do recommend choosing TCP or DOH for large DNS response. It is deserve a special treatment for IPv6 DNS especially. An technical article once introduced Ali-Cloud using a elastic security network to defend DDOS attack. The key idea is that its DNS-liked system can return thousands dynamic NS and A records for their services.
Yeti case with 25 name servers
As introduced, Yeti has 25 root servers. People may ask also why 25 ? It seems explained by previous calculation for IPv6-only root, less and equal than 26 within a packets size limit of 1500 octets containing necessary signature and opt RR. In fact Yeti developed to 25 root servers without such design behind.
Many of the Yeti experimental design choices were expected to trigger larger responses:
1) Choose a root naming scheme (free-form) can not be compressed.
2) Introduce more NS records for root zone enlarge priming response containing all NS records and their glue.
3) Yeti DNSSEC experiment like multiple ZSKs, KSK rollover, and reusing IANA Key and RRSIG, greatly enlarges the apex DNSKEY RRSet.
In the beginning we did not consider the size limit of any form. 25 is the initial target of Yeti testbed development allow an fair distribution of root in 5 Continents with qualified and responsible operators. And the number 25 is also viewed a fair number as a challenge case for “Magic 13”.
When Yeti developed with 25 servers, the size of priming response is up to 1754 octets with RRSIG and all address information (With Shane’s patch), surpassing the size limit of 1500 octets. It is under a risk of IPv6 fragmentation observed in Yeti testbed, which has around 7% packet drop rate if the packet size is larger than 1500 octets. But thanks to the diversity of Yeti testbed, Yeti servers response differently according to the local configuration and DNS software.
| Num | Operator | Response size | note |
|---|---|---|---|
| #1 | BII | 1754 | fragmented with all glue records |
| #2 | WIDE | 1782 | fragmented with all glue records |
| #3 | TISF | 1782 | fragmented with all glue records |
| #4 | AS59715 | 1222 | with partial glue, 1280 maybe set as a limit |
| #5 | Dahu Group | 1222 | with partial glue, 1280 maybe set as a limit |
| #6 | Bond Internet Systems | 1754 | fragmented with all glue records |
| #7 | MSK-IX | 1054 | with no glue record |
| #8 | CERT Austria | 1054 | with no glue record |
| #9 | ERNET | 1054 | with no glue record |
| #10 | dnsworkshop/informnis | NA | NA |
| #11 | Dahu Group | 2065 | fragmented with all glue |
| #12 | Aqua Ray SAS | 1222 | with partial glue, 1280 may be set as a limit |
| #13 | SWITCH | 1082 | normal BIND9 response with no glue records |
| #14 | CHILE NIC | 1054 | with no glue record |
| #15 | BII@Cernet2 | 1754 | return all glue records |
| #16 | BII@Cernet2 | 1754 | return all glue records |
| #17 | BII@CMCC | 1754 | return all glue |
| #18 | Yeti@SouthAfrica | 1754 | fragmented return all glue records |
| #19 | Yeti@Australia | 1754 | fragmented return all glue records |
| #20 | ERNET | 1054 | with no glue record |
| #21 | ERNET | 1782 | fragmented with all glue records |
| #22 | dnsworkshop/informnis | 1813 | fragmented with all glue records |
| #23 | Monshouwer Internet Diensten | 1668 | fragmented with only 22 glue records |
| #24 | DATEV | 1222 | with partial glue, 1280 may be set as a limit |
| #25 | jhcloos | 1222 | with partial glue, 1280 may be set as a limit |
Yeti DNS uses free-form names for each root server which can not be compressed. According to the protocol (BIND9 implementation) not all glue record is necessary be included in the additional section. Some root servers adopted a patch (developed by Shane Kerr) to contain all glue records but the response will be fragmented. Some root server set 1280 octets as a IPv6 packets size limit (1222 octets response), so they will contain as much address information as possible until the response reach the limit. I wondering why nobody use 1500 as a size limit which will fully use the room to contain more IPv6 address.
As to the servers response with no glue, it is in a questions that because all names is under the root. There should be at least 2 glue records contain in the additional section. As far as I know BIND9/Unbound work because they take the addresses listed in the hint file as trusted glue records. After checking rfc1034#section-5.3.3, it is proved compliant to the DND specification that “If the search for NS RRs fails, then the resolver initializes SLIST from the safety belt SBELT”. (The safety belt SBELT is a local a configuration file, the hint file)
Conclusion
In conclusion the limit of 13 is not technical applied. But people still has a inertia that 13 is the fix number of NS records. Now IPv6 fragmentation issue introduces new size limit that exert constraint on the size of response. Now the practical and safe choice is to keep the limit 19 for dualstack, 26 for IPv6-only taking 1500 octets as a packets limit. All glue records can be contained. If you want to add more NS records, you will lose some availability (less glue records).
Yeti is taken as an case study in this context. Yeti testbed now has 25 root name servers which already surpassed the limit. The response behaviors of different root servers vary. Although the consistency of DNS response is lost, it is good to have diversity for testbed purpose.